ALE also provides an XEmacs-based source-level debugger. This can only be used for parsing or definite clause resolution, and only with SICStus 3.8.6 or higher, and XEmacs 20.3 or higher. In future releases, a debugger with a more restricted functionality will be made available for users of SWI Prolog.
The ALE source-level debugger is implemented on top of the SICStus source-level debugger. The debugger provided with ALE has the complete functionality of the SICStus source-level debugger with ordinary Prolog programs; so you only need this one if you will need to debug both. SICStus debugger commands that are not explicitly mentioned in this section are not supported in ALE debugging.
ALE source code must occur in a single file in order to be debugged. To debug Prolog source code, please refer to the SICStus documentation. For both ALE and Prolog debugging, the prolog flag, source_info, needs to be turned on, using the command:
| ?- prolog_flag(source_info,_,on).The SICStus XEmacs interface should do this automatically.
When a Prolog hook is encountered while debugging an ALE grammar, the SICStus debugger is automatically invoked. The hook will be embedded in a Prolog call/1 statement. If the leap option of the SICStus debugger is used, the leap ends at the end of the hook -- ALE will creep when it resumes control.
To install the ALE source-level debugger, follow the directions in the distribution file, debugger/INSTALL.
To run the debugger without XEmacs, simply run SICStus Prolog from the directory with debugger.pl and type:
| ?- compile(debugger).This assumes that ale.pl and the debugger subdirectory are located in the same directory. If ALE.PL has not been loaded already, this will compile ale.pl as well. There will be a warning message about buffer-mode when it loads, which can be ignored. Then type:
| ?- noemacs.You can add a noemacs/0 directive to the end of debugger.pl to do this automatically.
To run the debugger with XEmacs, you must run SICStus Prolog and ALE within XEmacs as an inferior process. To do this:
| ?- compile(debugger).
| ?- emacs.that will turn on the XEmacs interface, if it has been disabled by noemacs/0.
There are seven basic commands in the ALE debugger, four of which are variants of normal ALE commands. These four, dcompile_gram/1, drec/1, dquery/1 and dgen/1, are the debugger variants of compile_gram/1, rec/1, query/1 and gen/1, respectively. The other three, dleash/1, dskip/1, and dclear_bps/0, will be explained below.
Currently, the ALE source-level debugger can only debug grammars down to the level of feature structure unification, i.e., feature structure unification is treated as an atomic operation. Constraints and procedural attachments on types using cons and goal cannot be debugged either, nor can inequation enforcement, edge subsumption checking, or extensionalization. These will be possible in a future version. For now, dcompile_gram/1 compiles a grammar in exactly the same way that ALE normally does to the point where it can be debugged. It then reopens the grammar file and uses the token-stream directly to index those parts of the grammar source code that it can debug by line number. dcompile_gram/1 also requires that all of the ALE source code for a grammar be in a single file, i.e., unlike ALE without the debugger, you cannot load other auxiliary files from within a grammar file. This restriction will also be lifted in a future version.
dcompile_gram/1 also allows for tracing through the EFD closure algorithm, again down to the level of feature structure unification.
After a grammar has been compiled for debugging with dcompile_gram/1, drec/1, dquery/1 and dgen/1 can be used for parsing, definite clause resolution or generation, respectively, with the debugger. dquery/1 works exactly as query/1 does: it first finds most general satisfiers of the arguments and then searches for a solution with Prolog-style SLD-resolution using the clauses provided by the user. drec/1 and dgen/1 work exactly as rec/1 and gen/1 do, except that lexical rules are not compiled out, so that they can be debugged. Also remember that ALE parses right-to-left with EFD-closed rules and empty categories, and that it uses a semantic-head-driven generator. With parsing, the debugger can also be used in conjunction with the chart mini-interpreter described above for extra control of the chart. With generation, the debugger successively shows the construction of the pivot template, pivot matching, pivot checking and the linking of the pivot with the root. Generation of non-semantic-head daughters is performed recursively.
The ALE debugger is loosely based on the procedural box model of execution that many Prolog debuggers use. There are four kinds of ports, call, exit, redo, and fail. The ALE debugger does not support exception ports. A call port occurs at every initial invocation of a step that ALE takes in parsing or definite clause resolution, a list of which is given below. An exit port occurs at the successful completion of such a step; a redo port occurs when a subsequent step has failed and ALE backtracks into the current step to find more solutions, and a fail port occurs when a step has failed to produce any or any more solutions.
Consider, for example, what happens when ALE applies the following description to a feature structure that occurs in the lexical entry for the word, foo
foo --->(a
;f:b),
g:c.
The first port we encounter is when ALE tries to add the type
a. This is a call port:
Call: add type, a, to lex entry?If this succeeds, then an exit port occurs:
Exit: add type, a, to lex entry?and processing moves on to g:c. If this fails, then we must backtrack through adding a for more solutions (for example, if there is a disjunctive constraint on that type):
Redo: add type, a, to lex entry?If there is another solution, then another exit port occurs. Otherwise, the next port is fail port:
Fail: add type, a, to lex entry?and processing continues with the other disjunct, f:b. Certain steps in ALE, notably the depth-first rule application of the chart parser, are failure-driven loops. To indicate that these ``failures'' are actually a normal part of execution, they are displayed as, e.g.:
Finished:close chart edge under rule application?
Enforcing descriptions at a feature also counts as a step:
Call: enforce description on f value of lex entry?If we agree to this, then the next step would be to add the type b
Call: add type, b, to value at f?and so on.
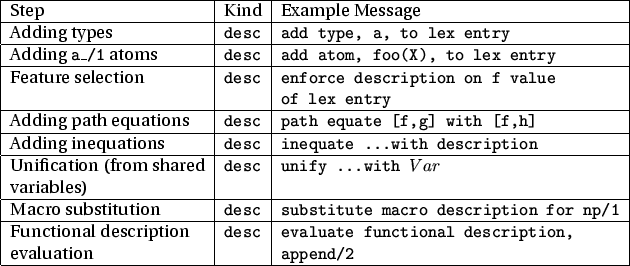
The steps in a description whose ports the ALE debugger keeps track of are given in Figure B.1:
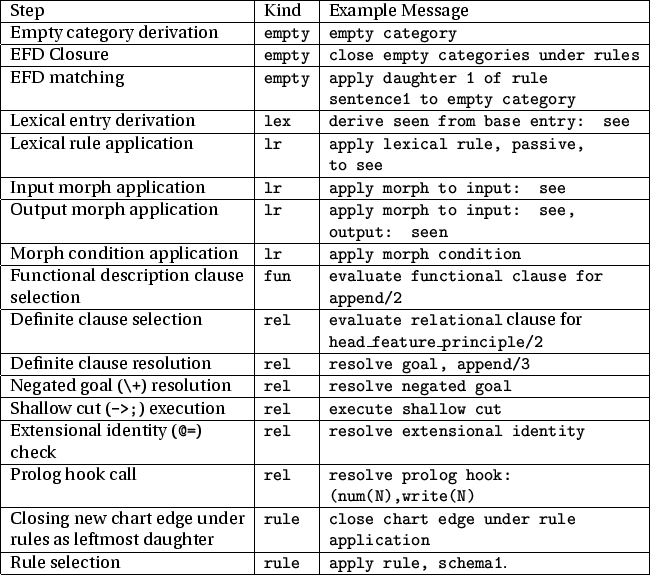
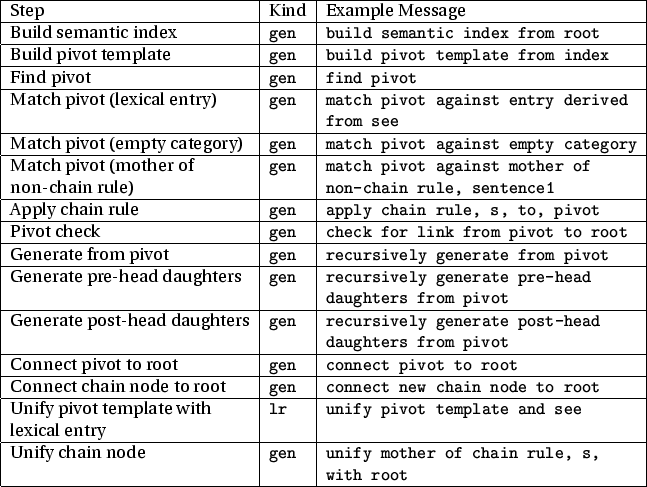
There are other kinds of steps besides description-level ones, that pertain to ALE's built-in control for parsing and definite clause resolution. These steps, along with their kind, are given in the table in Figure B.2. The steps for generation are given in Figure B.3. Almost all of these involve sub-steps that enforce descriptions. Some, such as chart-edge closure, involve other sub-steps such as rule selection. Lexical rule application includes input and output morph application, as well as morph condition (given in a when clause) application. The one generation step of kind, lr, takes place when the pivot template is matched against a (base or derived) lexical entry. Unlike the compiled generator, the debugger does not compile lexical rules into the non-chain-rule selection step, so that the user can see their application. Instead, a base lexical entry is first selected without reference to the pivot template, then zero or more lexical rules are applied bottom up, until a derived entry is eventually unified with the pivot template. Lexical rules are, thus, treated as a special kind of unary chain rule. The length of these special chains is still controlled by lex_rule_depth/1, not chain_length/1.
With so many steps, and four possible ports, stepping through an entire parse in a large grammar would be a very trying experience. The ALE debugger provides three basic ways to filter through the steps to find points of interest in a parse or definite clause query.
The first is leashing. Leashing allows the user to distinguish at which steps information is simply displayed and at which steps the debugger stops and asks the user what to do. Unlike the SICStus debugger, leashing in the ALE debugger is a property of steps, not ports. The command to control leashing is dleash/1. The argument to dleash/1 consists of a sign, + or -, plus the kind of step. A + sign indicates that the debugger should stop and ask what to do at steps of that kind; and a - sign indicates that it should simply display the port and proceed. For example, to turn leashing off for empty categories, type:
| ?- dleash(-empty). yesThere is also a special kind, all, that allows the user to turn on and off leashing on all kinds of steps at once. The default leashing at start-up is +all.
If a kind of step is leashed, then the debugger will stop at every port for every step of that kind, and ask what to do. The possible responses are given in Figure B.4:
Not all responses are available at all ports. The kind of port (call, fail, etc.) is what determines the possible responses. The responses, ? and h are always available, and list the other legal responses at the current port.
Even leashing may not be enough for very large parses or queries because of the sheer number of ports displayed. The ALE debugger also provides a facility for auto-skipping. Whereas turning leashing off at a kind of step is like automatically answering c (advance to next port) at those steps, auto-skipping is like automatically answering s, which advances to the next exit or fail port of the current step without stopping at or even displaying the ports in between. The command for this is dskip/1, and its argument is of the same form as the argument to dleash/1. The signs have a different meaning, of course. For example, dskip(+empty) means that you want the debugger to auto-skip steps of kind empty, i.e., not stop and ask, whereas dleash(+empty) means that you want to leash steps of kind empty, i.e., stop and ask. When a step where auto-skipping is set is encountered, it is displayed with an automatic reply without stopping, e.g.:
Call: empty category? <auto-skip> Exit: empty category? <auto-skipped> Edge added: Number:0, Left:1, Right:1, Rule:empty Call: close chart edge under rule application?
The final kind of filtering is the breakpoint. In the ALE debugger, breakpoints are a property of lines in a grammar source file, not steps or ports. For a finer grain of resolution, it would be necessary to give each potential breakable step its own line in the input. By setting breakpoints and then using the l response, the debugger will advance to the next step whose line has a breakpoint without displaying any steps in between. If that step is not leashed or has auto-skipping set, the debugger acts accordingly after displaying it.
There are currently two ways to set a breakpoint. One is to use the + response from within the debugger at a step at whose line you wish to set a breakpoint. The other is only available when the debugger is used with an installation of XEmacs that supports XPM resources. In this case, when a source file is compiled a small glyph will be displayed at the left edge of every breakable line. Clicking on this glyph once with the left mouse button sets a breakpoint. Clicking again clears it. A breakpoint can also be cleared with the - response.
It is often the case that a line will have several breakable steps on it, for example, feature paths:
synsem:local:cat:head:verb, qretr:e_listIf a breakpoint were set at the first line, then leaping from the call port for SYNSEM would still advance to the call port for LOCAL:
Call: enforce description on synsem value of lex entry? l Call: enforce description on local value of value at synsem?To avoid this, the response n is provided, for leaping automatically to the first port on a different line in the source file. The combination of n and l can be used to leap more effectively in files that pack many steps, particularly description steps, into one line.
All breakpoints can be cleared at once using the command, dclear_bps/0.